
Rechercher un motif dans un texte : l'algorithme de Boyer-Moore
- Fiche de cours
- Quiz et exercices
- Vidéos et podcasts
- Connaitre l’algorithme de recherche naïve d’un motif dans un texte.
- Connaitre l’algorithme de Boyer-Moore.
- Programmer l’algorithme de recherche naïve d’un motif dans un texte.
- Programmer l’algorithme de Boyer-Moore.
- Rechercher un motif dans un texte consiste à rechercher le ou les indices à partir desquels on retrouve le motif dans le texte. On dit que l’on recherche la ou les occurrences du motif dans le texte.
- La recherche naïve consiste à comparer un à un, de gauche à droite, les caractères du texte et ceux du motif, et de décaler la recherche dans le texte de un rang dès qu’une comparaison échoue.
- L’algorithme de Boyer-Moore consiste à comparer les caractères du motif et ceux du texte de droite à gauche, puis, en cas d’échec d’une comparaison de caractères, d’observer le caractère du texte qui ne correspondait pas à celui du motif et d’en déduire si on ne peut pas décaler le motif de plus de 1 rang dans la recherche du motif dans le texte.
Utiliser les chaines de caractères.
La recherche textuelle est très utilisée en génétique pour détecter la présence ou non de gènes, dans le web pour rechercher des chaines de caractères, dans les moteurs de recherche, etc.
Dans la chaine de caractères “abracadabra”, on trouve deux occurrences du motif “bra” pour i = 1 et i = 8 (la lettre “a” correspond à i = 0).
Pas à pas, cela donne :
-
i = 0 : Comparer de gauche
à droite chaque caractère du motif avec
ceux du texte à partir de i = 0.
- Si tous les caractères du motif correspondent, on a trouvé une occurrence du motif dans le texte.
- On recommence la comparaison au rang suivant : i = 1.
-
i = 1 : Comparer chaque
caractère du motif avec ceux du texte à
partir de i = 1.
- Si tous les caractères du motif correspondent, on a trouvé une occurrence du motif dans le texte.
- On recommence la comparaison au rang suivant : i = 2.
- ...
On considère le motif “TAGGAC” et le texte “TAGTAGCACTGTAGGACTGC”.
On recherche la ou les occurrences du motif dans le texte.
i = 0 :
i = 1 :

i = 1 n’est donc pas une occurrence du motif dans le texte.
i = 2 :

i = 2 n’est donc pas une occurrence du motif dans le texte.
i = 3 :

i = 4 :

i = 4 n’est donc pas une occurrence du motif dans le texte.
i = 5 :

i = 5 n’est donc pas une occurrence du motif dans le texte.
i = 6 :

i = 6 n’est donc pas une occurrence du motif dans le texte.
i = 7 :

i = 7 n’est donc pas une occurrence du motif dans le texte.
i = 8 :

i = 8 n’est donc pas une occurrence du motif dans le texte.
i = 9 :

i = 9 n’est donc pas une occurrence du motif dans le texte.
i = 10 :

i = 10 n’est donc pas une occurrence du motif dans le texte.
i = 11 :

On peut poursuivre pour chercher une autre occurrence.
En Python, la fonction rech_naive(motif, texte) implémente la recherche naïve du motif dans le texte. Il renvoie le tableau des indices pour lesquels on a trouvé une occurrence du motif dans le texte.
| Python | Explication |
| def rech_naive(motif, texte): | On définit la fonction rech_naive. |
|
reponse = [] t = len(texte) m = len(motif) |
On initialise le tableau reponse avec un tableau
vide. On affecte à t la taille de texte et à m la taille du motif. |
| for i in range(0, t – m + 1): | Pour i allant de 0 à t – m, |
|
if texte[i : i + m] == motif: reponse.append(i) |
si la partie du texte (de taille m commençant à i) et le motif correspondent, alors on ajoute i au tableau reponse. |
| return reponse | on retourne le tableau reponse. |
Voici l’appel de cette fonction sur Python Tutor pour le motif “TAGGAC” et le texte “TAGTAGCACTGTAGGACTGC”.
On obtient [11], ce qui signifie qu’il y a une occurrence en i = 11 du motif “TAGGAC” dans le texte.
Dans la chaine de caractères “abracadabra”, on recherche le motif “cad”.
Étape 1 :

On peut donc décaler le motif de 3 rangs puisque le r ne correspondra jamais.
Étape 2 :

On peut donc l’aligner avec le caractère a du motif “cad”.
Étape 3 :
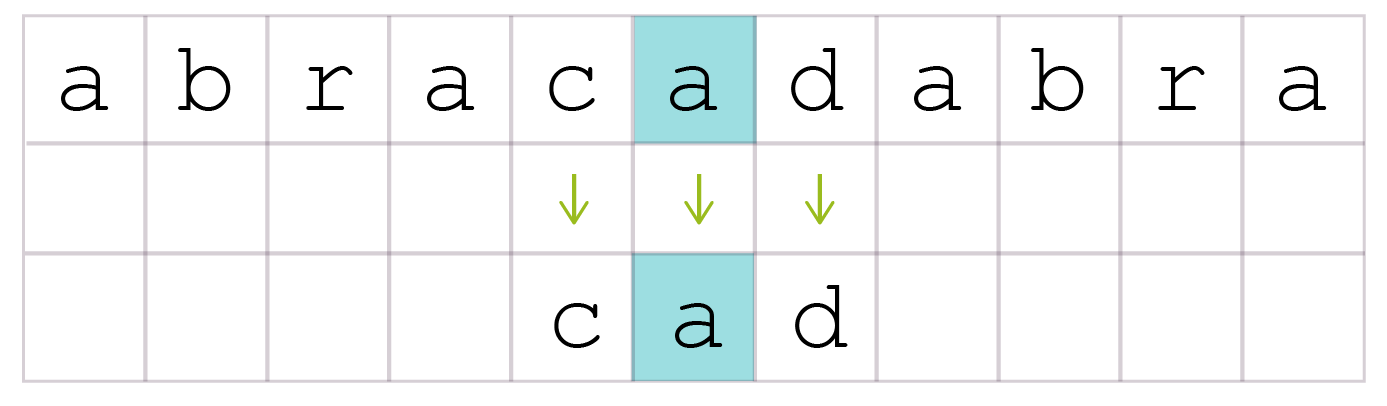
Il y a deux cas :
- Si x (caractère du texte) n’est pas un caractère du motif, alors, pour la comparaison, on place le motif juste à droite du caractère x du texte qui a provoqué l’échec. Ainsi le décalage de i (dans le texte) sera de j + 1 (indice j du caractère du motif + 1).
- Si x (caractère du texte) est un caractère du motif, alors, pour la comparaison, on déplace le motif vers la droite pour que le x le plus à droite du x et le x du texte correspondent. Si ne n’est pas possible, on décale le motif de 1.
On considère le motif “TAGGAC” et le texte “TAGTAGGACTGTACTAGGAC”.
On recherche les occurrences du motif dans le texte.
i = 0 :

i = 2 :

i = 3 :

i = 4 :

i = 9 :

i = 11 :

Pour programmer l’algorithme de Boyer-Moore, on doit d’abord traiter le motif pour avoir des informations sur la position la plus à droite de chacun de ses caractères à partir d’un indice donné. Ces informations seront stockées dans un tableau de dictionnaires.
En Python, la fonction table_boyer_moore(motif) prend en paramètre le motif, et retourne le tableau dont chaque élément est un dictionnaire des positions des caractères les plus à droite pour chaque indice du motif donné.
| Python | Explication |
| def table_boyer_moore(motif): | On définit la fonction. |
| d = [{} for i in range(len(motif))] | On initialise le tableau d avec des dictionnaires vides. |
| for j in range(len(motif)): |
Pour chaque indice du motif j allant
de 0
à len(motif)–1, |
| for k in range(j): | pour tout k allant de 0 à j–1, (on parcourt le motif) |
| d[j][motif[k]] = k | On attribue la valeur k à la clé motif[k] du (j+1)-ième dictionnaire du tableau d. (dans le tableau d[j], on associe au (k+1)-ème caractère du motif son indice k) |
| return d | on retourne le tableau d. |
Ensuite, la fonction decalage(d, j, chr) prend en paramètres :
- le tableau précédent d ;
- l’indice j du motif qui correspond à l’indice du caractère du motif pour lequel la comparaison avec le texte a échoué ;
- et chr le caractère du texte pour lequel la comparaison a échoué.
Cette fonction renvoie le décalage à opérer pour continuer l’algorithme de Boyer-Moore.
| Python | Explication |
| def decalage(d, j, chr): | On définit la fonction decalage. |
| if chr in d[j]: | Si le caractère chr (caractère du texte pour lequel la comparaison a échoué) est une clé du dictionnaire d[j] |
| return j – d[j][chr] |
on retourne j – d[j][chr] (l’écart entre j (l’indice d’arrêt de la comparaison dans le motif) et le décalage pour retrouver le caractère d’arrêt dans le texte **) |
| else: | Sinon |
| return j + 1 | on retourne j + 1 (on décale d’un rang vers la droite). |
d[j][chr] correspond à l'indice du caractère chr dans le motif le plus près à gauche du (j+1)-ème caractère du motif.
Par exemple, pour le motif "caractere" :
- d[4]['a'] vaut 3 car le dernier 'a' rencontré avant le 5e caractère (‘t’) est d'indice 3.
- d[2]['a'] vaut 1 car le dernier 'a' rencontré avant le 3e caractère (‘r’) est d'indice 1.
Enfin, la fonction rech_boyer_moore(motif, texte) implémente l’algorithme de Boyer-Moore de recherche du motif dans le texte.
| Python | Explication |
| def rech_boyer_moore(motif, texte): | On définit la fonction. |
|
d = table_boyer_moore(motif) i = 0 reponse = [] |
On attribue à d la table de Boyer-Moore (qui donne la position de chaque élément du motif). On initialise la variable i (indice où on place le motif par rapport au texte) à 0 et reponse avec un tableau vide. |
| while i < len(texte) – len(motif): | Tant que i est strictement inférieur à len(texte)–len(motif), |
| k = 0 |
on initialise la variable k à 0. (k est le décalage que l’on réalisera. Par exemple, dans la recherche naïve, k vaut toujours 1. On avance le motif de 1 en 1.) |
| for j in range(len(motif)–1, –1, –1): | Pour j (indice dans le motif) allant de len(motif)–1 à 0 en décroissant de 1, |
| if texte[i + j] != motif[j]: | si le caractère du texte d’indice i+j ne correspond pas au caractère du motif d’indice j, alors |
|
k = decalage(d, j, texte[i+j]) break |
on attribue à k le décalage correspondant. (break signifie qu’on sort de la boucle) |
|
if k == 0: reponse.append(i) k = 1 |
Si k est égal à 0, alors on ajoute i au tableau reponse, puis on attribue 1 à k (on avance le motif de 1). |
| i = i + k | on incrémente i (indice où on place le motif par rapport au texte) du décalage k. |
| return reponse | on retourne le tableau reponse. |
Voici l’appel de cette fonction sur Python Tutor pour le motif “TAGGAC” et le texte “TAGTAGCACTGTAGGACTGC”.
On obtient [11], ce qui signifie qu’il y a une occurrence en i = 11 du motif “TAGGAC” dans le texte.
Évalue ce cours !

Des quiz et exercices pour mieux assimiler sa leçon
La plateforme de soutien scolaire en ligne myMaxicours propose des quiz et exercices en accompagnement de chaque fiche de cours. Les exercices permettent de vérifier si la leçon est bien comprise ou s’il reste encore des notions à revoir.

Des exercices variés pour ne pas s’ennuyer
Les exercices se déclinent sous toutes leurs formes sur myMaxicours ! Selon la matière et la classe étudiées, retrouvez des dictées, des mots à relier ou encore des phrases à compléter, mais aussi des textes à trous et bien d’autres formats !
Dans les classes de primaire, l’accent est mis sur des exercices illustrés très ludiques pour motiver les plus jeunes.

Des quiz pour une évaluation en direct
Les quiz et exercices permettent d’avoir un retour immédiat sur la bonne compréhension du cours. Une fois toutes les réponses communiquées, le résultat s’affiche à l’écran et permet à l’élève de se situer immédiatement.
myMaxicours offre des solutions efficaces de révision grâce aux fiches de cours et aux exercices associés. L’élève se rassure pour le prochain examen en testant ses connaissances au préalable.

Des vidéos et des podcasts pour apprendre différemment
Certains élèves ont une mémoire visuelle quand d’autres ont plutôt une mémoire auditive. myMaxicours s’adapte à tous les enfants et adolescents pour leur proposer un apprentissage serein et efficace.
Découvrez de nombreuses vidéos et podcasts en complément des fiches de cours et des exercices pour une année scolaire au top !

Des podcasts pour les révisions
La plateforme de soutien scolaire en ligne myMaxicours propose des podcasts de révision pour toutes les classes à examen : troisième, première et terminale.
Les ados peuvent écouter les différents cours afin de mieux les mémoriser en préparation de leurs examens. Des fiches de cours de différentes matières sont disponibles en podcasts ainsi qu’une préparation au grand oral avec de nombreux conseils pratiques.
Des vidéos de cours pour comprendre en image
Des vidéos de cours illustrent les notions principales à retenir et complètent les fiches de cours. De quoi réviser sa prochaine évaluation ou son prochain examen en toute confiance !





Fiches de cours les plus recherchées


Envie de progresser et de réussir votre année scolaire ?
Testez gratuitement pendant 24h notre plateforme de soutien scolaire !

Un espace dédié aux parents pour suivre les progrès
Tout le programme scolaire du CP à la Terminale
Des profs expérimentés disponibles à la demande par tchat, audio ou vidéo